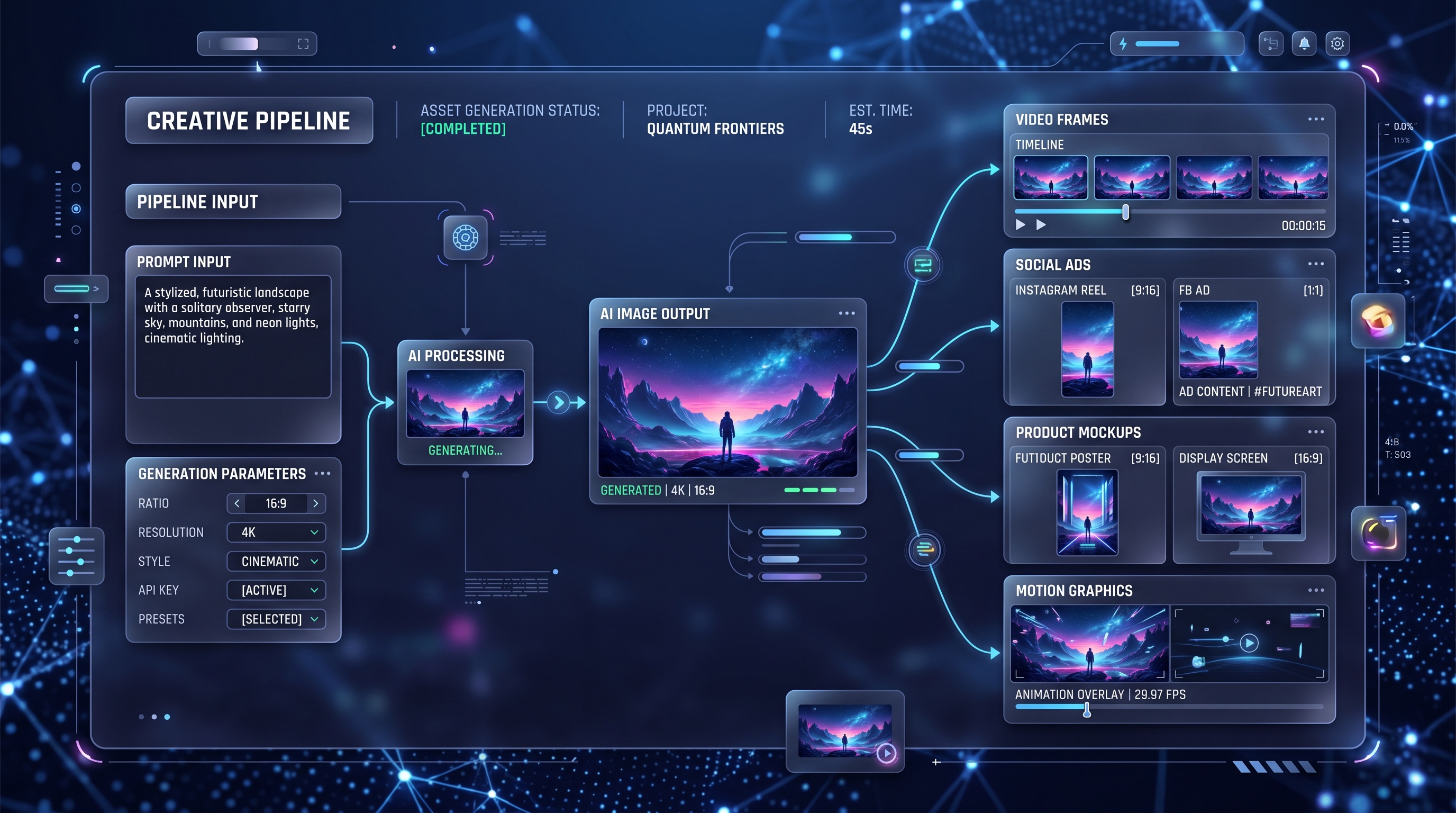
การเปิดตัวฟีเจอร์สร้างภาพล่าสุดของ OpenAI กลายเป็นหนึ่งในประเด็นที่ถูกพูดถึงมากที่สุดในโลกครีเอทีฟด้าน AI อย่างรวดเร็ว ระหว่างประกาศเปิดตัวผลิตภัณฑ์อย่างเป็นทางการกับเอกสารสำหรับนักพัฒนา หลายคนเริ่มเห็นชื่อเรียกที่เหมือนจะพูดถึงก้าวกระโดดเดียวกันอยู่หลายแบบ นั่นจึงเป็นเหตุผลว่าทำไมผู้ใช้จำนวนมากถึงพร้อมใจกันค้นหาคำอย่าง GPT Image 2, OpenAI image 2.0 และ OpenAI GPT Image 2 ไปพร้อม ๆ กัน
เวอร์ชันย่อมีอยู่ว่า สแตกสำหรับสร้างภาพตัวใหม่ของ OpenAI โฟกัสกับคุณภาพภาพที่ดีขึ้น การทำตามพรอมต์ที่แม่นยำขึ้น การเรนเดอร์ตัวอักษรในภาพที่สะอาดขึ้น และการแก้ไขภาพที่เชื่อถือได้มากกว่า ในประกาศอย่างเป็นทางการ ประสบการณ์ฝั่งผู้ใช้ทั่วไปถูกนำเสนอในชื่อ ChatGPT Images 2.0 ส่วนในเอกสารนักพัฒนา โมเดล API เบื้องหลังก็ถูกระบุชื่อว่า gpt-image-2 แต่สำหรับผู้ใช้ทั่วไป คำถามหลักไม่ใช่เรื่องชื่อเรียก แต่อยู่ที่ผลลัพธ์มากกว่า: อะไรที่ “ดีขึ้นจริง” และจะลองใช้ได้ที่ไหน?
ทำไม GPT Image 2 ถึงรู้สึกเหมือนเป็นการอัปเดตที่มีนัยสำคัญ
การสร้างภาพด้วย AI ผ่านมาหลายระลอกแล้ว ระลอกแรกทำให้คนทึ่งด้านสไตล์ ระลอกที่สองทำให้การสร้างภาพเร็วขึ้นและง่ายขึ้น ระลอกใหม่นี้คือเรื่อง “การควบคุม” นั่นแหละคือเหตุผลจริง ๆ ที่ทำให้ GPT Image 2 by OpenAI ถูกจับตามองขนาดนี้
แทนที่จะมองเครื่องมือสร้างภาพเป็นแค่เครื่องมือศิลป์แบบยิงทีเดียวจบ OpenAI กำลังผลักมันให้เข้าใกล้เวิร์กโฟลว์สร้างสรรค์ที่ใช้งานได้จริงมากขึ้น คุณสามารถใช้ทำโปสเตอร์ งานโซเชียลครีเอทีฟ ม็อกอัป หน้าแมนกา อาร์ตคอนเซปต์ คอมโพสิชันคล้าย UI แผ่นอ้างอิง และการแก้ไขภาพที่ต้องการให้ทำตามคำสั่งได้ชัดขึ้น กล่าวคือ มันไม่ได้มีแค่ “ทำภาพให้สวย” แต่เป็น “ทำภาพให้ตรงกับที่ฉันขอจริง ๆ”
การเลื่อนระดับแบบนี้สำคัญกับทั้งครีเอเตอร์ นักการตลาด นักออกแบบ และนักพัฒนา การควบคุมที่ดีขึ้นมักหมายถึงภาพที่เฟลน้อยลง การแก้ไปมาแบบงง ๆ ลดลง และเส้นทางจากไอเดียไปสู่ผลงานที่ใช้การได้จริงก็ลื่นไหลขึ้นมาก
อะไรคือสิ่งที่ “ใหม่จริง” ใน GPT Image 2
การอัปเกรดที่ใหญ่ที่สุดคือการเรนเดอร์ข้อความ ภาพจาก AI ตลอดหลายปีที่ผ่านมามักสวยสะดุดตา แต่ออกจะไม่น่าไว้ใจเมื่อถูกขอให้วางคำที่อ่านออก ในโปสเตอร์ เมนู ป้ายฉลาก ป้ายบอกทาง หน้าสเปรดนิตยสาร หรือเลย์เอาต์แนวภาพสินค้า ด้วย OpenAI GPT Image 2 ส่วนนี้ดูใช้งานได้จริงขึ้นมาก
การอัปเกรดสำคัญอันดับสองคือการรองรับหลายภาษา นี่สำคัญกว่าที่หลายคนคิด โมเดลที่จัดการระบบตัวเขียนหลายแบบได้อย่างเป็นระเบียบ จะมีประโยชน์อย่างยิ่งสำหรับงานมาร์เก็ตติ้งระดับโลก การศึกษา การเล่าเรื่อง และการสร้างแบรนด์
การปรับปรุงที่สามคือการทำตามคำสั่งที่ดีขึ้น ตรงนี้แหละที่ทำให้โมเดลเริ่มรู้สึกเหมือนผู้ช่วยครีเอทีฟ มากกว่าจะเป็นตู้สล็อตแมชชีน หากคุณขอให้สร้างฉากที่มีอารมณ์ คอมโพสิชัน อัตราส่วน และองค์ประกอบการออกแบบแบบหนึ่ง ๆ โมเดลโดยรวมแล้วจะพยายามเคารพเงื่อนไขเหล่านั้นหลายข้อพร้อมกันมากขึ้น
ยังมีเรื่อง “การเข้าใจเลย์เอาต์” ที่แข็งแรงขึ้นด้วย ทำให้การอัปเดตครั้งนี้ยิ่งเกี่ยวข้องกับคนที่ทำคอนเซปต์หน้าปก ดราฟต์โฆษณา ภาพประกอบพรีเซนเทชัน แผงเรื่องราว เมนู โปสเตอร์ และม็อกอัปสินค้า จะนึกภาพการเอาโมเดลนี้ไปใช้ในสายการผลิตคอนเทนต์จริง ๆ ได้ง่ายขึ้น แทนที่จะจำกัดอยู่แค่เธรดศิลปะทดลอง
สุดท้าย การแก้ไขภาพมีบทบาทมากขึ้น OpenAI กำลังมองการสร้างภาพและการแปลงภาพเป็นส่วนหนึ่งของเวิร์กโฟลว์เดียวกัน นั่นทำให้การอัปเดตครั้งนี้ใช้งานได้จริงมากขึ้นสำหรับคนที่อยากเริ่มจากภาพอ้างอิง แก้รายละเอียด หรือไล่ไต่ไปสู่แอสเซ็ตสุดท้าย แทนที่จะต้องเริ่มใหม่หมดทุกครั้ง
ทำไมการอัปเดตนี้แตกต่างจากเวิร์กโฟลว์สร้างภาพของ OpenAI รุ่นก่อน ๆ
สิ่งที่ทำให้การอัปเดตนี้รู้สึกต่าง ไม่ใช่แค่ตัวเลขเบนช์มาร์กหรือภาพตัวอย่างที่หวือหวาอย่างเดียว แต่เป็น “ประสบการณ์โดยรวม” เครื่องมือภาพ AI รุ่นก่อนมักบังคับให้ผู้ใช้ต้องเลือกระหว่าง “ภาพสวย” กับ “ความแม่นตรงของโจทย์” คุณอาจได้ภาพที่สวยมาก แต่ตัวหนังสือเสีย เลย์เอาต์เพี้ยน หรือฉากไม่สนใจพรอมต์ไปครึ่งหนึ่ง
ทิศทางใหม่ของ chatgpt image model รู้สึกใช้งานได้จริงกว่าก็เพราะมันพยายามปิดช่องว่างนั้น มันพยายามผสมคุณภาพการมองเห็นเข้ากับการเชื่อฟังพรอมต์ที่แข็งแรงขึ้น การรองรับการแก้ไข และโครงสร้างภาพที่ขัดเกลาขึ้น
นี่สำคัญเป็นพิเศษสำหรับ “คนไม่ใช่นักวาด” ผู้ใช้จำนวนมากของเครื่องมือเหล่านี้ไม่ใช่คนวาดรูป แต่เป็นผู้ก่อตั้งสตาร์ตอัป คอนเทนต์ครีเอเตอร์ ครู นักการตลาด นักพัฒนาอินดี้ และเจ้าของธุรกิจขนาดเล็ก พวกเขาไม่ได้ต้องการทดลองสไตล์ไม่รู้จบ แต่ต้องการเครื่องมือที่สร้างภาพฮีโร่ ป้ายเมนู หน้าโคมิก ไอเดียภาพปก หรือภาพสินค้าได้โดยไม่ต้อง “สู้กับเครื่องมือ” ตลอดเวลา
จะเข้าใช้ GPT Image 2 แบบทางการได้ที่ไหน
ถ้าอยากใช้ช่องทางทางการ ปัจจุบันมีสองเส้นทางหลัก
เส้นทางแรกคือผ่านฝั่งผลิตภัณฑ์ของ OpenAI ซึ่งการอัปเดตถูกนำเสนอในชื่อ ChatGPT Images 2.0 นี่คือภาพจำที่ง่ายสำหรับผู้ใช้ทั่วไป: OpenAI ปรับปรุงประสบการณ์การสร้างภาพภายในระบบของตัวเอง ทั้งเรื่องการเรนเดอร์ข้อความ เอาต์พุตหลายภาษา อัตราส่วนภาพ และการควบคุมเชิงครีเอทีฟ
เส้นทางที่สองคือฝั่งนักพัฒนา ในเอกสารของ OpenAI ชื่อ gpt-image-2 ถูกนำเสนอเป็นโมเดลสร้างภาพรุ่นปัจจุบันสำหรับงานสร้างและแก้ไขภาพที่รวดเร็วและคุณภาพสูง เปิดให้ใช้ผ่านแพลตฟอร์มของ OpenAI สำหรับนักพัฒนาที่อยากใส่ฟีเจอร์สร้างภาพลงในแอปและเวิร์กโฟลว์
นั่นแหละคือเหตุผลที่ความสนใจค้นหาคำอย่าง chatgpt image api เพิ่มขึ้น คนอยากรู้ว่ารุ่นใหม่ของเครื่องมือภาพจาก OpenAI เป็นแค่ฟีเจอร์สำหรับผู้ใช้ทั่วไป หรือสามารถอินทิเกรตเข้าผลิตภัณฑ์ได้ด้วย คำตอบคือ OpenAI ชัดเจนว่ารองรับทั้งฝั่งผู้ใช้ปลายทางและฝั่งนักพัฒนา
จะเข้าใช้งานเวอร์ชันเว็บแบบง่าย ๆ ตอนนี้ได้ที่ไหน
สำหรับหลายคน เอกสารทางการมีไว้เพื่อทำความเข้าใจการอัปเดต แต่ไม่ได้เหมาะกับการ “ลงมือสร้าง” พวกเขาต้องการอินเทอร์เฟซที่เรียบง่ายสำหรับลองพรอมต์อย่างรวดเร็ว เปรียบเทียบผลลัพธ์ แล้วไปต่อได้เลย
ตรงนี้ VideoWeb จึงเข้ามามีบทบาท หน้าแลนดิ้ง GPT image 2 OpenAI ถูกวางตัวเป็นตัวเลือกสร้างภาพผ่านเบราว์เซอร์ที่ใช้งานง่าย สร้างบนเวิร์กโฟลว์ภาพของ GPT-4o สำหรับผู้ใช้ทั่วไป จุดเริ่มต้นที่ใช้งานจริงมักเป็นแบบนี้: บรรยายภาพ ปรับการตั้งค่า สร้าง แล้วไล่ปรับไปเรื่อย ๆ
การเข้าถึงแบบนี้สำคัญ เพราะ “ความสะดวก” มีผลต่อความถี่ที่คนจะใช้โมเดลจริง ๆ โมเดลที่ทรงพลังแต่ซ่อนอยู่หลังความยุ่งยากทางเทคนิค มักจะกลายเป็นเรื่องทฤษฎีสำหรับผู้ใช้สายแมส ในขณะที่อินเทอร์เฟซที่สะอาดตาจะลดอุปสรรคที่ว่าลง
ใครบ้างที่ควรสนใจ GPT Image 2
การอัปเดตนี้มีความเกี่ยวข้องเป็นพิเศษกับกลุ่มต่อไปนี้
ครีเอเตอร์ควรสนใจ เพราะภาพที่มีตัวหนังสือเยอะ ๆ ภาพหน้าปก ภาพโปสเตอร์ และกราฟิกโซเชียลกำลังกลายเป็นเคสใช้งานที่ “จริง” ขึ้น นักออกแบบควรสนใจ เพราะวินัยเรื่องเลย์เอาต์และการแก้ไขภาพดูน่าเชื่อถือขึ้น นักการตลาดควรสนใจ เพราะตัวอักษรที่ชัดกว่าและการทำตามคำสั่งที่ดีขึ้นทำให้ร่างแคมเปญง่ายขึ้นมาก นักพัฒนาควรสนใจ เพราะ OpenAI กำลังปฏิบัติต่อการสร้างภาพเหมือนเป็นความสามารถด้านผลิตภัณฑ์จริงจัง ไม่ใช่แค่ของเล่น
และผู้ใช้ทั่วไปก็ควรสนใจด้วย หากคุณเคยรู้สึกว่าเครื่องมือภาพจาก AI สนุก แต่ไม่น่าไว้ใจ การอัปเดตนี้กำลังชี้ไปในทิศทางที่ใช้งานได้จริงมากขึ้น
บทสรุปที่ใหญ่กว่านั้น
สิ่งสำคัญที่สุดของการเปิดตัวครั้งนี้ไม่ใช่ “ชื่อเรียก” แบบเป๊ะ ๆ บางคนจะเรียกมันว่า GPT Image 2 บางคนจะพูดว่า OpenAI image 2.0 คนอื่นอาจคิดถึงมันในฐานะเอนจินสร้างภาพตัวใหม่ของ ChatGPT ชื่ออาจต่างกัน แต่ข้อความหลักชัดเจน: OpenAI กำลังผลักดันการสร้างภาพจาก AI ไปสู่ “ประโยชน์ใช้สอยที่สูงขึ้น” ไม่ใช่แค่ “ความแปลกใหม่ที่สูงขึ้น”
นั่นหมายถึงตัวอักษรที่ดีขึ้น การควบคุมที่ดียิ่งขึ้น เอาต์พุตหลายภาษาที่แน่นขึ้น คอมโพสิชันที่ยืดหยุ่นมากขึ้น และสะพานเชื่อมจากการสร้างสู่การแก้ไขที่ใช้งานได้จริง หากแนวโน้มนี้เดินหน้าต่อ โมเดลภาพก็จะกลายเป็นเครื่องมือผลิตงานประจำวัน มากกว่าจะเป็น “ของเล่นครีเอทีฟ” ที่หยิบใช้เป็นครั้งคราว
สำหรับผู้ใช้ที่ต้องการ “ทำความเข้าใจ” การอัปเดต หน้าทางการของ OpenAI คือที่ที่ดีที่สุดสำหรับตรวจสอบสิ่งที่ได้รับการยืนยันแล้ว สำหรับผู้ใช้ที่อยากลองเวิร์กโฟลว์บนเว็บที่รวดเร็ว GPT Image 2 บน VideoWeb เป็นก้าวต่อไปที่ใช้ได้จริง และสำหรับคนที่กำลังเทียบกันทั้งระบบนิเวศ ก็น่าลองมองไปที่สแตกด้านภาพและวิดีโอที่กว้างกว่าบน VideoWeb ด้วย
เครื่องมือและโมเดลแนะนำบน VideoWeb
- GPT-4o Image Generator
- AI Image Generator
- Seedream 4.5 AI
- Nano Banana Pro AI
- Qwen Image 2
- Seedance 2.0
- Google Veo 3.1
- Vidu Q3
- Kling 3.0
- Image to Video
บทความที่เกี่ยวข้อง
- Mastering GPT4o Image Generation: How to Unlock Creative Potential with the New GPT 4o Image Generator
- How to Use Seedance 2.0 for Anime Clips: Prompt Examples and Scene Ideas
- Vidu Q3 AI vs Kling 3.0: Which AI Video Model Should You Use on VideoWeb AI?
บทความที่คนมักอ่านต่อ
- HeyDream AI Image Generator Guide: Best Models for Text-to-Image and Image-to-Image
- Nano Banana Pro on DreamMachine AI: A Practical Way to Create Better AI Images
- How to Use Sea Imagine AI's Image Generator: A Beginner-Friendly Tutorial
- AIFacefy AI Image Generator 2026: Best Models Ranked + When to Use Each
- GPT Image 2: What’s New, What’s Confirmed, and Why Creators Are Watching Closely
- GPT Image 2 Explained: What’s New, and How It Compares With Nano Banana Pro